大数据
Hadoop¶
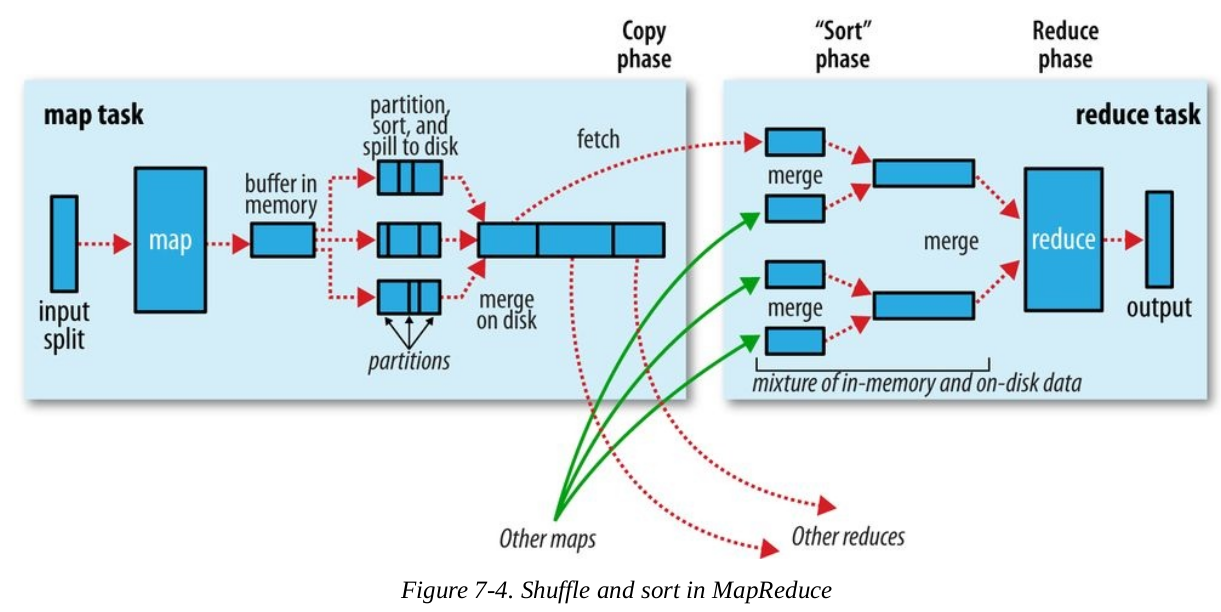
Hadoop分为Map和Reduce两个阶段,细分又包括之间的Shuffle和Sort过程,即在Map阶段将输入数据切分成多分小数据,如何传送到Reduce阶段
具体过程参见下图
1. Mapper¶
Map阶段将输入的<key, value>转成<intermediateKey, intermediateValue>
每一个mapper都有一个circular buffer(环形缓存),环形缓冲区是一个先进先出的循环缓冲区(默认大小为100M),Mapper的输出会首先写进这个缓存里面,当里面的内容达到一个阈值(默认为80%)时,一个后台线程就会开始向磁盘spill这些内容
同时Mapper将继续向该缓存区写内容.当缓存区写满时,Map被阻塞,直到spill过程完成才会被唤醒.Spills 将会循环写进 mapreduce.cluster.local.dir定义的目录下面,也就是说会产生多个spill磁盘文件
在spill过程写进磁盘之前还会做一些事情
- Partitioner: 首先线程会先把写的内容分成多个partition,partition的个数和reducer的个数相同,默认方法就是hash(key) % |reducer|
- Sort: 针对每一个分组,线程会实现内存的排序,默认是按照key来排序
- 如果存在combiner的话,combiner会在sort之后,在每一个分组进行执行,combiner的执行会导致写到磁盘的数据减少
如下图中,写入磁盘后会有多个文件,同时每个文件里又分成多个partition
每一次环形缓存达到阈值,就会产生一个spill的文件,也就是说可能会产生很多个spill文件。在任务结束之前,这些文件会被合并为统一的带有分组和排好序的文件作为输出
如下图,一个mapper spill的多个小文件会merge成一个大文件,并且有序划分为多个partitions
2. Reducer¶
Reducer又分为copy、sort和reduce阶段
Copy
如上图,一个mapper的多个partition会被copy到对应的reducer上,然后来自不同mapper的partition会merge在一起,再由reducer处理
因为不同mapper结束时间是不一样的,所以有多个线程来进行拷贝,通过设置mapreduce.reduce.shuffle.parallelcopies,可以实现线程数量的改变,默认的情况下该值为5
如果map的输出文件很小,那么它们就会被拷贝到reduce任务的JVM内存中,否则会写入到磁盘。当在JVM内存中的数据,达到一个阈值时(由mapreduce.reduce.shuffle.merge.percent属性控制)或者map的输出达到一个阈值时(由mapreduce.reduce.merge.inmem.threshold属性控制),这些map输出数据开始merge,并spill到磁盘中
当磁盘上的文件逐渐增多时,后台程序会将多个spill文件sort和merge成更大的文件
Sort
当所有的map输出文件都已经被拷贝完成,reducer进入到sort阶段,也就是混合map输出文件,使数据保持有序的状态
这个合并过程是一轮一轮进行的,即round方式,最后一轮的合并结果直接推送给reduce作为输入,如下图,有50个map输入文件,而混合因子是10( mapreduce.task.io.sort.facto),那么会用5轮来完成合并,如下图

流处理方法¶
数据抽样¶
搜索引擎收到查询流,要求查询在过去一个 月中,典型用户所提交的重复查询的比率是多少? 并假设,我们只希望存储1/10的数据流
大数据面试题¶
1. 海量数据处理 分而治之/Hash映射 + Hash_map统计 + 堆/快速/归并排序¶
例题1. 海量日志数据,提取出某日访问百度次数最多的那个IP
- IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理;
- 可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)%1024值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB种IP地址;
- 对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址;
- 可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP
例题2. 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词
- 分而治之/hash映射:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M
- hash_map统计:对每个小文件,采用trie树/hash_map等统计每个文件中出现的词以及相应的频率
- 堆/归并排序:取出出现频率最大的100个词(可以用含100个结点的最小堆)后,再把100个词及相应的频率,存入文件,这样又得到了5000个文件。最后就是把这5000个文件进行归并(类似于归并排序)的过程了
2. 多层划分¶
因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行
例题1. 2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数
整数个数为232,也就是,我们可以将这232个数,划分为2^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决
3. Bloom filter/Bitmap¶
例题1. 在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数
采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^{32} * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可
5. 外排序¶
多路归并排序